
EN
● 如何利用智能文档处理(IDP)优化保险业理赔与运营流程?
● 告别手动录单:OCR如何解决物流单据处理慢、错、杂三大痛点?
你是否想过,如何将一沓厚厚的纸质文件,轻松变成可以在电脑上编辑、搜索的电子版?答案就是光学字符识别(Optical Character Recognition),简称OCR。
简单来说,OCR就像一台“数字化复印机”,但它做的远不止复印。它能自动扫描文档,并将扫描件转换成机器可以读取、编辑和分享的文件。举个例子:当你用手机或扫描仪拍下一张购物小票时,电脑会存为一张图片。这张图片里的文字,你无法直接复制,也无法进行字数统计。但只要通过OCR工具处理,这张图片就能“活”过来,变成一个包含所有文本信息的文档,里面的文字可以随意编辑。无论是相机拍摄的照片、纯图片的PDF,还是扫描件,OCR技术都能从中提取出数据,让原本静态的内容变得可操作,省去了人工录入的繁琐。

尽管我们生活在一个数字时代,但发票、合同、法律文件等纸质材料在许多商业活动中仍然普遍存在。这些“纸山”不仅占用大量物理空间,管理起来也费时费力。因此,“无纸化”正成为越来越多企业的选择。
过去,将纸质文件扫描成图片,依然需要耗费大量时间进行手动整理和信息录入。如今,许多免费的OCR工具就能轻松解决这个问题。它们能将图片中的文字转换成可被其他商业软件读取的文本数据,为个人和企业节省大量时间和金钱。这项技术可以简化操作流程、辅助数据分析、实现流程自动化,从而全面提升生产力。

OCR的工作过程,大致可以分为四个核心步骤:
1.图像分析: 首先,扫描仪读取文档,将其转化为计算机能理解的二进制数据。接着,OCR软件会分析这个扫描文件,区分出浅色的背景区域和深色的文字区域。
2.预处理: 为了提升识别准确率,OCR技术会通过一系列技巧对图像进行“美化”和修正:
a.平滑文字边缘,去除图像中的噪点。
b.校正扫描过程中可能出现的倾斜。
c.整理图像中的线条和方框。
d.对于多语言OCR技术,还需要识别文档所用的文字脚本。
3.文字识别: 这是最核心的一步,主要通过两种方法实现——特征提取和模式匹配。
a.特征提取 (Feature extraction):系统不再进行像素级的硬性比对,而是分析字符的拓扑和几何特征,例如直线、曲线、闭环、交叉点的数量和相对位置。例如,大写字母“A”可以被描述为“由两条斜线和一个横线相交构成”。这种方法对字体的变化具有更强的鲁棒性,是现代AI驱动OCR技术的基础。
b.模式匹配 (Pattern matching): 这种方法会先分离出单个的字符图像,我们称之为“字形 (glyph)”,然后将其与一个预存的、标准字形的数据库进行比对。对于字体统一、印刷清晰的文本,这种方法速度快、效果好。但其弱点也十分明显:一旦遇到库中没有的新字体、艺术字或图像质量不佳的字符,识别率会急剧下降
4.后处理: 当所有内容分析完毕后,系统会将提取出的文本数据转换成一个正式的电子文件。一些OCR工具还能生成一个带注释的文件,让你直观地比较扫描件的原始样貌和识别后的版本。如果在识别时遇到问题,通常需要检查一下扫描件的质量是否足够高,比如光线是否充足、图像是否清晰、有没有歪斜等。
这项改变文档处理方式的技术,由发明家雷·库兹韦尔 (Ray Kurzweil) 在1974年开发。他创立了库兹韦尔计算机产品公司 (Kurzweil Computer Products, Inc.),其技术几乎能识别任何印刷字体。库兹韦尔认为,这项技术的最佳应用是为盲人制造一台机器学习设备。于是,他发明了一台能够大声朗读文本的阅读机,实现了从文本到语音的转换。
1980年,他对将纸质文本商业化更感兴趣的施乐公司 (Xerox) 收购了他的公司。
然而,OCR技术直到20世纪90年代初才开始普及,当时它被广泛用于数字化历史悠久的报纸。从那时起,OCR经历了飞速发展。今天的OCR已经能够实现近乎完美的转换,并通过先进的方法实现文档处理流程的自动化。在这项技术出现之前,人们必须手动重新打字录入所有文档,这不仅耗时耗力,也更容易出错。如今,OCR已变得触手可及,持续为个人和商业应用提升效率。
数据科学家根据应用场景,将OCR区分为几种不同类型:
●简单光学字符识别 (Simple OCR): 这种软件将不同的字体和文本图像模式存为模板。它通过模式匹配算法,逐个字符地在内部数据库中进行比对。由于字体和手写风格的数量近乎无限,这种方案有其局限性。
●智能字符识别 (Intelligent Character Recognition, ICR): 作为现代OCR技术的一部分,ICR像人类一样“阅读”文本。它利用机器学习软件,让机器像人一样思考。一个被称为“神经网络”的系统会反复研究文本和处理图像,通过分析线条、曲线、闭环等特征,并综合不同层级的数据,最终得出识别结果。
●智能单词识别 (Intelligent Word Recognition, IWR): 这项技术与ICR原理相似,但它研究的是整个单词的图像,而不是先将图像预处理成单个字符。
●光学标记识别 (Optical Mark Recognition, OMR): 这种技术主要用于识别文档中的水印、标志、Logo等特定标记。
以下是一些备受好评的OCR工具,无论个人用还是企业用都非常出色:
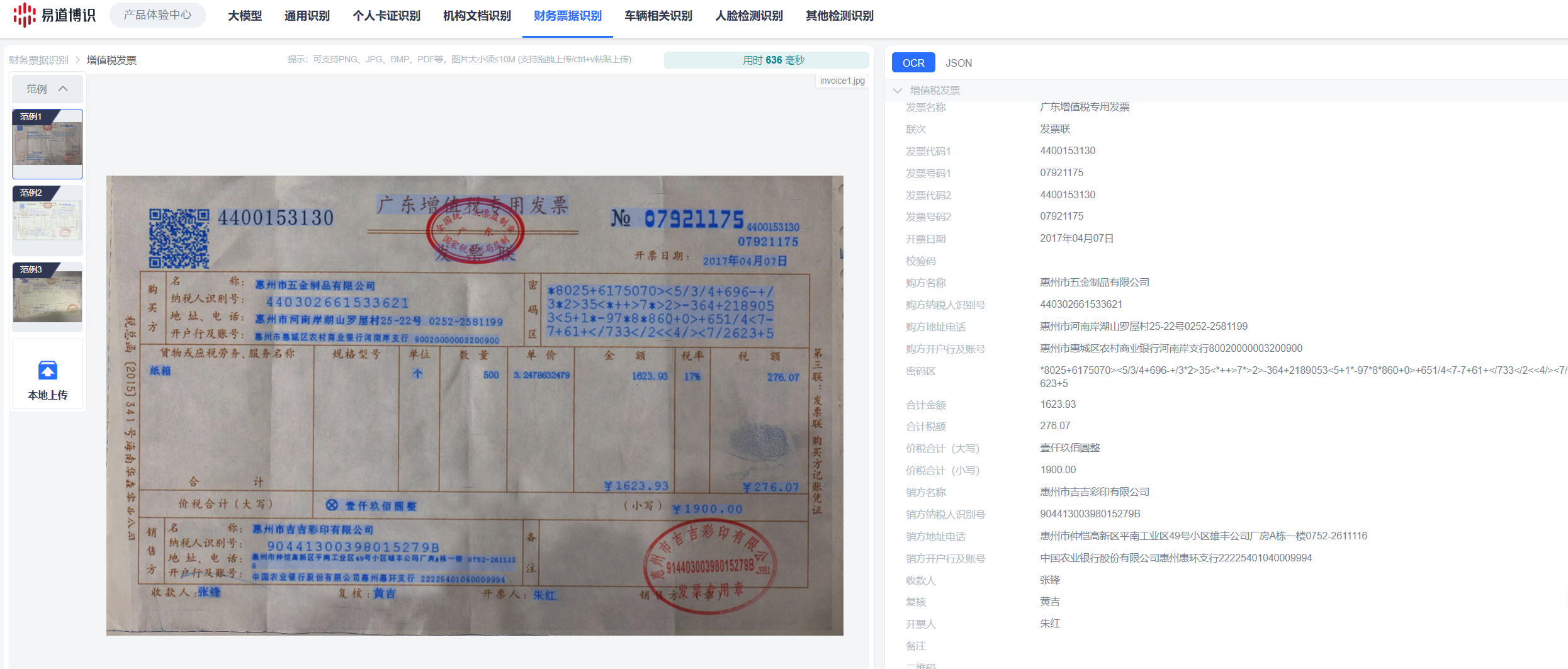
1.易道博识:提供7大类,60多种主流OCR识别场景,覆盖主流识别需要,比如身份证、银行卡、发票/报销票据等,还支持财务报表识别、银行流水单识别,文字识别精度超99.5%,非常适合企业的文档OCR识别需求。
2.Adobe Acrobat Pro: 提供全面的OCR功能,可以极大地简化工作流程。除了基本的OCR功能,你还可以对文档添加注释和反馈、比较两个版本的差异,甚至有专门扫描表格的工具。它与免费的Adobe Scan应用配合默契,用手机扫描的文档能自动识别文本。
3.OmniPage Ultimate: 以其极高的转换准确度而闻名。它允许用户创建自定义的工作流程,让处理好的文档自动以正确的格式发送到指定位置。
4.Abbyy FineReader: 一款强大的工具,能将纸质文档转换为PDF、Microsoft Office格式等多种数字格式。它支持批量处理大量文档,并能识别多达192种语言。
5.Readiris: 支持多种文件格式,并可以为文档添加签名、安全保护、评论、水印和注释。
除了最常见的将印刷品转换为可编辑文本外,OCR的应用场景十分广泛:
●辅助功能: 帮助视障人士获取信息。
●数据自动化: 自动从车牌、发票、护照等文件中提取数据,并录入搜索引擎或数据库。
●商业领域: 随着业务增长,手动处理文档变得不切实际。OCR通过自动化数据提取,将员工从繁琐的数据录入工作中解放出来,让他们能专注于更重要的任务。数据数字化后,不仅降低了成本,也更集中、更安全,减少了丢失或被盗的风险。
●教育领域: OCR是学生的学习利器。它可以将纸质作业扫描成数字文档,并通过朗读功能帮助有阅读障碍(如诵读困难)的学生学习。学生还可以方便地调整文本颜色、大小,添加高亮和数字书签。
●医疗领域: 医疗行业使用OCR来处理海量的病历,如检查报告、治疗记录和保险支付单。它简化了病历管理,缩短了数据录入电子健康记录(EHRs)的时间,并提高了准确性。医生可以通过OCR快速搜索到患者的既往病史,药方也可以被扫描以减少用药错误。
在过去几十年里,OCR和机器学习都取得了指数级的增长,未来只会更加智能。下一代OCR技术建立在人工智能和机器学习之上,早已超越了简单的字符匹配。
结合最新的大模型,现在的OCR不仅能不仅能“看见”扫描的文本,更能“理解”文本的含义。随着大模型技术的发展,这一趋势将更加明显。总而言之,通过将静态的纸质文档转换为智能、可搜索的数字文档,OCR技术减少了人工劳动、时间和成本,让企业能够为客户和员工提供更高效、更便捷的信息获取体验。





