
EN
高精度的财报识别不止OCR,它是一套集图像预处理、NLP语义理解、深度版式分析与逻辑勾稽校验于一体的智能全流程。它能将非结构化的PDF或图片报表,转化为准确率极高、可直接用于分析的结构化数据,有效解决了通用OCR无法处理复杂表格和财务逻辑的痛点。
一套成熟的财报识别系统包含如下流程
1.数据采集与智能预处理
a.多格式兼容: 系统首先接收各种格式的财报,如PNG/JPG扫描件、图像型PDF,excel等
b.图像清洗: 这是决定识别率的关键一步。 必须自动进行去噪点、倾斜校正和图像增强,并剔除页眉页脚干扰,只保留核心表格区域。
2.高精度信息提取
a.专用OCR引擎: 不同于通用OCR,财报识别引擎针对“¥”、“%”、千分位分隔符及密集数字进行了专项优化。
b.结构还原: 系统通过深度学习识别表格的行列结构(包括无线框表格),精准锁定科目名称与对应金额的坐标关系。
3.NLP深度语义理解
a.同义词对齐: 解决“应收账款”与“应收帐款”等异体字问题。
b.属性判断: 自动通过NLP识别数字属性(金额 vs 日期)及单位(元 vs 万元),实现数据标准化。
4.数据结构化与标准映射
a.容器装载: 将提取出的非结构化数据,自动映射到预设的标准财务报表模板(如资产负债表标准字段)中,生成JSON、Excel或数据库记录。
5.智能校验与人工干预
a.自动配平校验,系统内置“资产=负债+所有者权益”等财务等式进行交叉验证。一旦勾稽关系不平,系统自动标记疑点并推送人工复核,确保数据零差错。

许多企业试图用通用OCR工具处理财报,但通常以失败告终。一个常见的误区是,认为“只要能把字转成文本就够了”。实际上,财报识别面临三大难题:
●格式无定式: 企业的报表版式千变万化,有的完全无框线,有的科目跨页断裂。通用工具依赖固定模板,遇到新版式直接失效。
●干扰噪声多: 财务报表上常有红色印章、水印、手写批注覆盖关键数字。通用OCR难以分离这些噪点,导致识别乱码。
●容错率为零: 财务数据的一个小数点错位(如将100.00识别为10000),会导致决策灾难。通用OCR缺乏财务逻辑校验功能,无法发现此类错误。
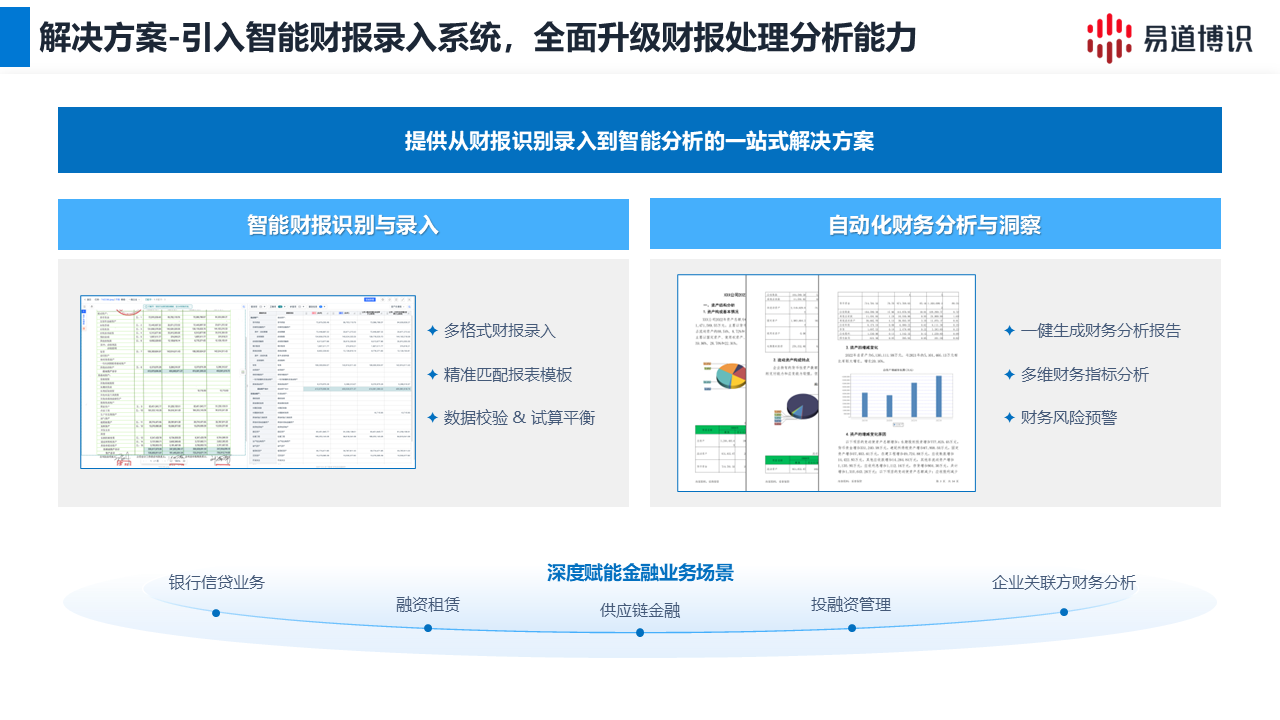
针对上述痛点,易道博识推出智能财报录入系统,其核心优势在于将AI技术与财务逻辑深度融合:
1. 深度版式分析,有效识别复杂财报
我们观察到,依赖模板的传统OCR维护成本极高。易道博识采用了基于深度学习的版式分析技术,不依赖固定模板。它能像人类一样看懂布局,自动处理无线框、跨页断裂及结构复杂的异形报表。
2. 金融级OCR引擎,抗干扰能力强
基于海量金融票据数据的训练,易道博识的引擎具备极强的抗干扰能力:
●自动去章去噪: 能有效剔除印章和水印干扰,还原底下被遮挡的文字。
●特殊符号优化: 对财务术语、手写数字和特殊金融符号的识别精度远超行业平均水平。
3. 内置千种勾稽规则,自动配平校验
系统内置了覆盖三张主表的上千种财务勾稽关系规则。
●自动交叉验证: 数据提取后,系统自动运行逻辑运算。
●错误锁定: 任何不符合财务逻辑的数据(如借贷不平)会被立刻提醒,转由人工判断
Q: 财报录入后的数据校验和人工复核方便吗?
A: 校验非常便捷。[易道博识] 提供可视化的交互编辑界面,自动高亮显示勾稽关系错误的科目,并支持提取数值与原图坐标对照显示。对于复杂表格,用户甚至可手动调整表格线触发二次解析,大幅降低人工复核成本。
Q: 金融行业有哪些成熟的财报录入与OCR识别落地案例?
A: 目前,[易道博识] 已在中国农业发展银行、华夏银行等多家头部机构落地。其核心算法经过了高强度金融场景的深耕验证,能有效支撑信贷审批与风险分析等关键业务的高效运转。





