
EN
“垃圾进,垃圾出”是AI领域的第一定律。AI应用的智能上限,直接由其学习的数据质量决定。对于依赖企业内部文档(如PDF、报告、手册)的AI系统,低质量数据是致命的。
然而,企业的大部分文档在解析时,经常会标题层级错乱,表格被拆分变形,多栏格式无法识别。导致无法形成完成的语义,数据得不到有效利用。
将原始、混乱的非结构化文档,转化为AI能高效利用的“数据养料”,需要一个系统性的“数据精炼厂”。
第一步:如何为模型预训练构建高质量语料?
此阶段的目标是“清洗与结构化”。一个强大的系统需要具备以下能力:
●智能版面分析:精准处理图文混排、多栏布局等复杂版式,确保文本按正确的阅读顺序被提取。
●关键元素识别:准确识别并标记标题、段落、列表、表格等不同元素。
●表格结构化重组:对于跨越多页的复杂表格,能自动完成拼接,将其还原为一个完整的、可供分析的数据单元。
处理后的产出是完全遵循原文逻辑、结构清晰的语料库,能从源头上保障模型训练的质量。
第二步:如何为RAG应用构建更高质量的知识库?
RAG(检索增强生成)应用成功的关键在于检索的精准度。这依赖于知识库的构建方式,核心技术是“逻辑分块(Logical Chunking)”。
●传统方式(固定长度分块):强行按字数(如512个字符)切分文档。这种方法极易将一个完整的段落或表格从中间切断,破坏语义完整性。
●逻辑分块(推荐方式):以段落、表格、或一个完整的“标题-正文”组合等具备内在逻辑的语义单元作为边界进行分块。
例如,当用户提问时,逻辑分块能确保系统召回的是一个语义完整、自包含的知识单元(比如一整个完整的表格),从而为大模型提供最充分的判断依据,这是从根本上减少内容幻觉、提升答案准确性的最有效途径。
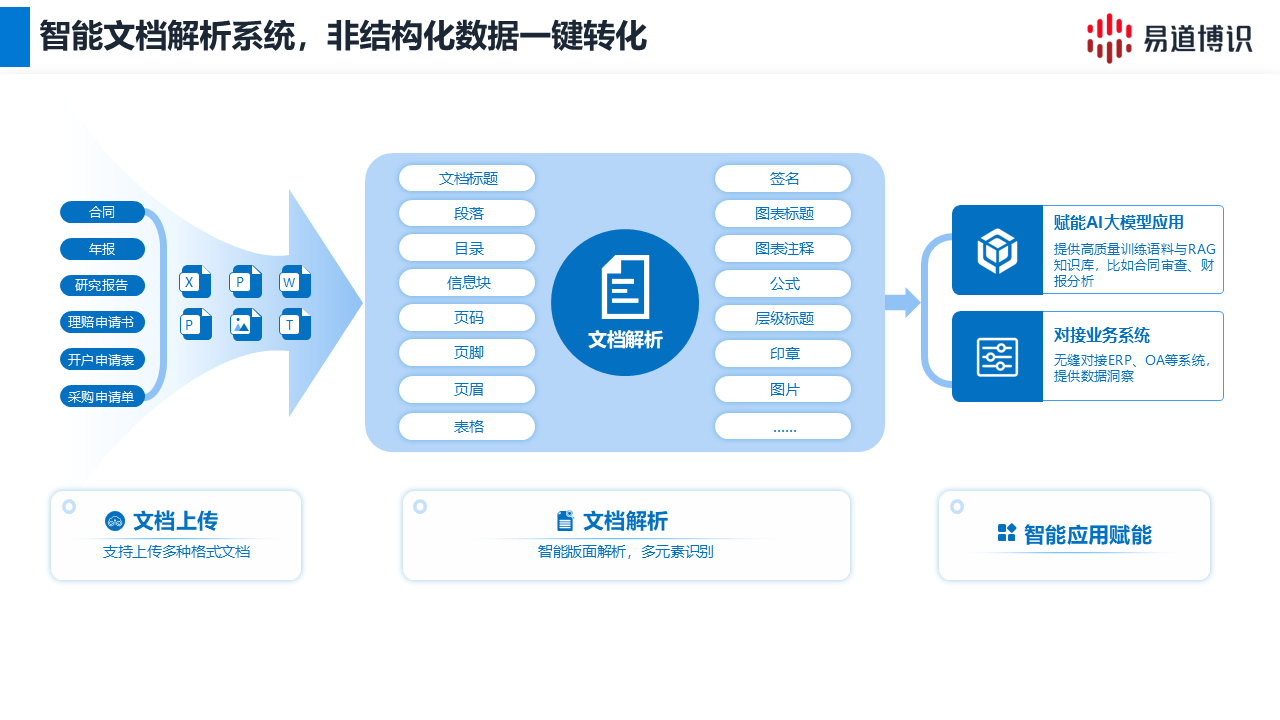
易道博识智能文档解析系统,专注于精准还原复杂文档的版面结构。
1.全面的格式支持与元素识别:支持PDF、图片等多种格式,可全面识别标题、段落、表格等元素,实现内容结构化。
2.复杂版式版面还原:系统能确保图文混排和多栏布局的正确阅读顺序,避免语义混淆;可自动拼接跨页表格,并深度解析含多级表头、嵌套单元格的复杂表格,完整保留其数据逻辑;同时还能重建文档的标题层级,构建清晰的逻辑骨架。最终,系统能够输出与原始版面在内容和结构上高度一致的结构化数据。
3. 智能抽取与多样化格式输出:用户可以选择输出Markdown格式,以最大程度地保留原始文档的版式和内容结构;也可以选择输出JSON格式,该格式包含了每个文字、字块乃至段落的精确坐标位置信息和置信度得分,不仅支持后续的数据可视化与交互式修改,还能对低置信度字符提供警示,便于人工高效校验。

1.智能文档解析系统支持图片格式的文档吗?
答: 支持。系统能够处理通过扫描或拍照生成的文档图片,如JPG、PNG格式,并同样进行高精度的版面解析与结构化处理。
2.文档解析和普通的OCR识别有什么区别?
答: 本质区别在于“理解”。普通OCR软件的目标是“识别文字”,而智能文档解析系统的目标是“理解文档”。它不仅识别文字,更重要的是理解文字的角色(是标题还是正文)、元素间的关系(如图文对应、表格结构)以及正确的阅读顺序。





