
EN
财务报表入系统,将图片、PDF、excel、zip等格式的报表,自动转化为结构化的财务数据,并通过内置的财务勾稽关系进行校验,最终无缝对接到ERP或财务软件中,实现全流程自动化。
一个高效的财报自动识别系统,其工作流程被设计为一套环环相扣的自动化步骤,以确保从原始报表到可用数据的精准转化。
1.第一步:数据采集与预处理
a.多格式兼容:系统首先要能接收多种格式的输入,包括纸质报表的扫描件、图片、可编辑或不可编辑的PDF文件,甚至是Excel表格。
b.图像优化:采集后,系统会自动对图像进行优化处理,如倾斜校正、亮度对比度调整、去除背景噪点和无关信息(如水印、边框),为后续的精准识别打下坚实基础。
2.第二步:核心信息提取
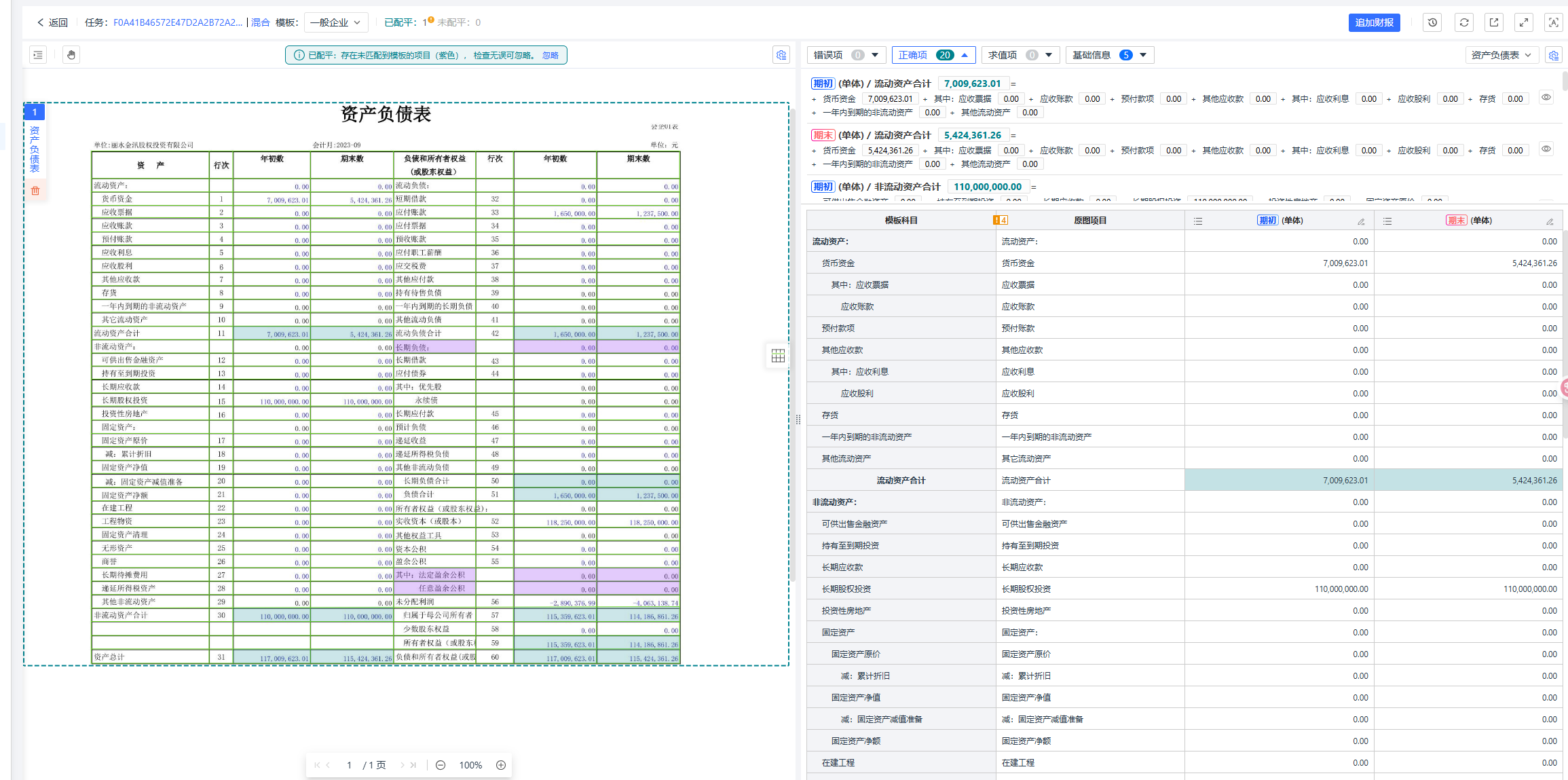
a.文字识别 (OCR):利用光学字符识别(OCR)技术,提取报表中的所有文字和数字。。
b.表格结构识别:准地还原报表的表格结构,可识别跨页、无线等复杂财报,准确判断每个数据单元格所在的行与列。
c.自动科目映射:系统能自动识别出“主营业务收入”和“营业收入”其实指向同一个财务科目,并进行标准化映射,避免了人工核对的麻烦。
3.第三步:智能配平校验
a.系统内置了财务逻辑和勾稽关系校验引擎。它会自动验证数据的准确性,例如:
i.资产负债表平衡:资产总计 = 负债和所有者权益总计
ii.利润表与权益变动:净利润 是否与权益变动表中的数据匹配。
b.当发现校验不通过或数据异常时,系统会自动标记并提示人工复核,确保最终数据的100%可靠。
4.第四步:系统集成与输出
a.处理完成的结构化数据可以无缝对接到企业现有的财务系统、ERP、数据分析平台或数据库中,实现从数据录入到分析应用的全链路自动化。
确保数据的绝对准确性,不能仅靠单一技术,而需要一个多层级的校验体系。
●技术层面:采用高精度的OCR识别引擎和先进的表格布局分析模型是基础。这保证了从图像到文字/表格的转化尽可能准确。
●业务逻辑层面:一个常见的误区是,认为只要OCR识别率高,最终数据就没问题。实际上,真正的准确性保障来自于嵌入在系统中的财务逻辑校验。通过预设上百个财务公式和勾稽关系,系统能够像一个资深的会计师一样,对数据进行交叉验证,从而发现技术识别无法发现的逻辑错误。
●人机协同层面:对于系统自动发现的校验异常点,可以人工复核流程。既保证了极高的效率,又为数据的最终准确性上了一道保险锁。

Q1: 如果公司的财报模板不是标准的,系统还能识别吗?
A1: 可以。易道博识智能财报识别系统具备强大的模板适应能力。首次识别非标准模板后,可以通过简单的手动调整或拖拽配置,让系统“学习”并记住新的模板规则。后续再遇到同类报表,系统即可自动匹配并高效识别。
Q2: 能处理手写的财务报表吗?
A2: 对手写体的识别是OCR技术中的一个难点。目前,对于印刷体报表的识别准确率非常高(可达99%以上),但对于工整手写体的识别率会略有下降。对于潦草或不规范的手写体,识别效果则无法保证,通常需要人工辅助录入。





