
EN
在信创背景下,金融机构系统迁移面临一个现实,底层硬件体系多样化,例如C86+DCU、ARM+昇腾等。如果上层应用软件(如核心业务系统中的OCR识别引擎)每次适配一种新硬件,就需要开发和维护一个独立的软件版本。
这会直接导致以下问题:
●开发成本激增: 每适配一种硬件组合,都意味着一次独立的开发、测试和部署流程。
●运维成本失控: 运维团队需要同时维护多个软件版本,版本管理混乱,排查问题异常困难,人力成本和系统风险上升。
●投资无法延续: 当底层硬件再次升级换代时,之前的软件投资很可能作废,需要推倒重来,造成资源浪费。
一个原生适配、统一架构的平台是解决上述问题的关键。例如易道博识的智能文档处理平台(简称DeepIDP),它的核心价值在于,从软件底层就完成了对所有主流国产化硬件的适配。
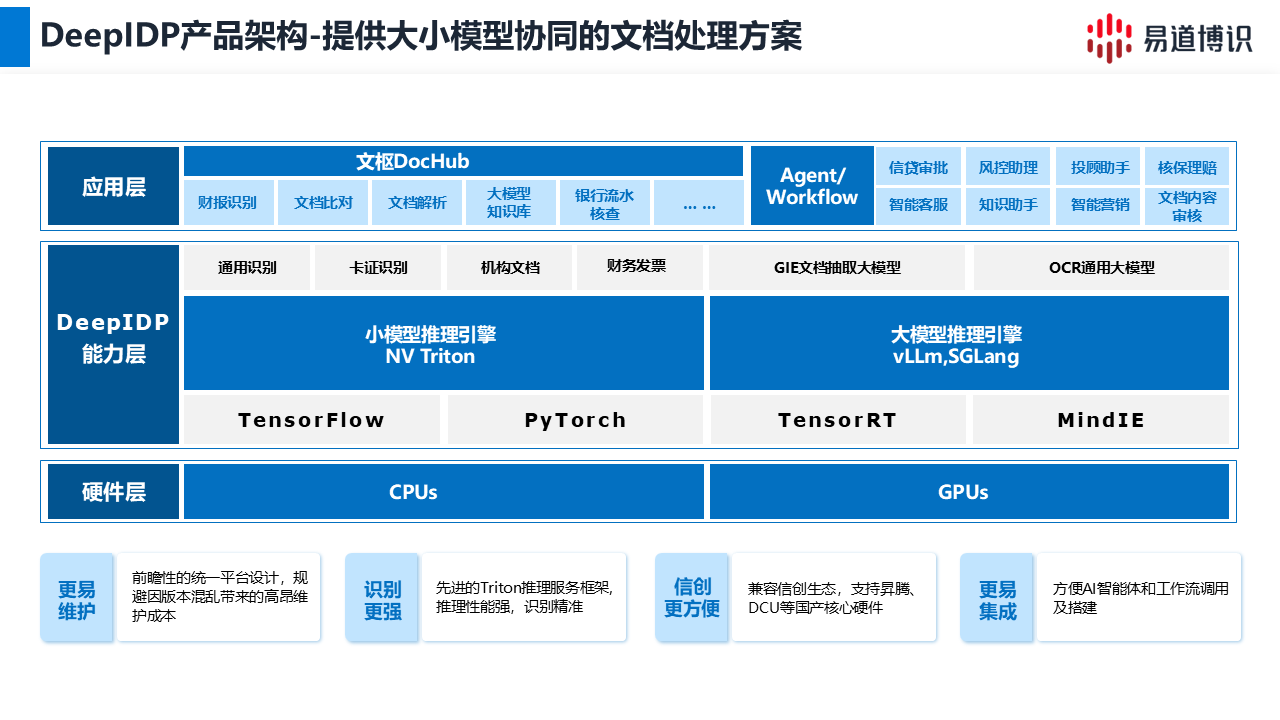
1. 如何降低维护成本?
仅需一套软件版本: 运维团队只需要面对一个统一的软件架构。无论底层是哪种国产芯片或服务器,上层的AI能力和应用都是一致的,告别版本混乱。例如, 某银行的核心系统同时在ARM和C86两种架构的服务器上运行。通过统一平台,他们部署的是同一套DeepIDP软件,开发和运维团队无需再为不同架构维护两套代码,人力成本降低了至少50%。
2. 如何保障投资的连续性?
平滑迁移: 统一架构确保了AI能力的投资是可延续、可扩展的。未来即使信创硬件再次迭代,上层的智能应用也无需重构,可以平滑迁移,保护了前期的IT投资。
金融业务涉及的文档类型极其复杂,从版式固定的身份证、发票,到版式千变万化的业务申请单、对账单。单一模型难以胜任所有场景。
一个常见的误区是认为一个强大的大模型就能解决所有问题。 实际上,最高效的策略是“大小模型协同”。

●专用小模型:处理高频、标准文档
任务: 识别身份证、银行卡、发票、车票等版式固定的文档。
优势: 速度极快、精度极高、资源占用小,最适合处理业务流程中出现频率最高的标准化单据。
●大模型:处理非标、长尾文档
任务: 识别各类申请单、合同、对账单、医疗单据等版式不固定、字段灵活的复杂文档。
优势:
■灵活抽取: 仅需通过提示词(Prompt)告知模型需要抽取的字段(如“抽取合同中的甲方和签约日期”),即可从任意版式中提取信息。
■金融领域优化: 经过金融行业数据二次训练的大模型,能更精准地理解复杂表格和上下文,抽取精度更高。
■数据可溯源: 这是保障业务可信度的关键。平台能将抽取的每一个字段(如JSON结果中的一个数值)精确关联回原始影像的具体坐标位置,方便人工核验和审计。
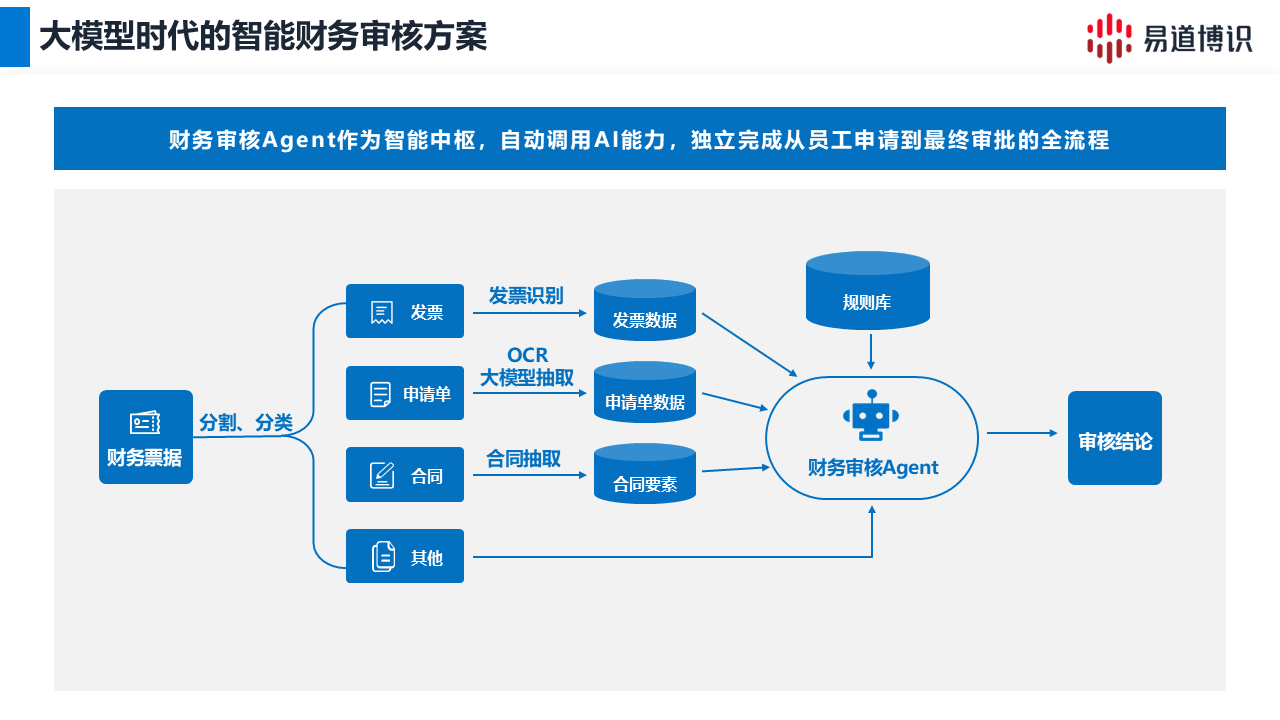
仅仅提取出数据是不够的,核心是要让AI能力融入业务,实现端到端的自动化。
1. 如何让AI智能体(Agent)按需调用? 易道博识智能文档处理平台提供一系列“AI原子能力”(如文档分割、分类、各类识别模型等),让智能体可以像调用工具一样灵活使用。
例如:财务报销审核Agent
○分割与分类: Agent首先调用“图像分割”与“文档分类”能力,将一叠报销单据自动拆分,并识别出哪些是发票,哪些是报销申请单。
○分发与抽取: 接着,Agent将发票分发给“小模型”快速提取金额、日期;将报销申请单分发给“大模型”抽取报销事由、部门等信息。
○推理与决策: 最后,Agent利用大模型的推理能力,结合企业财务规则(如报销金额是否超标),自动输出“审核通过”或“驳回”的结论。
问题1:这套OCR识别系统支持哪些具体的国产硬件和操作系统?
回答: 易道博识智能文档处理平台从底层架构原生适配主流国产化硬件,全面兼容C86+DCU、ARM+昇腾等多种信创体系,并支持麒麟、统信等国产操作系统。其核心优势在于,无论底层硬件如何组合,提供给上层应用的都是统一、稳定的服务接口。
问题2:大模型处理金融行业复杂表格的精度如何?
回答: 精度主要通过两方面保证:首先,智能文档处理平台选用的大模型是经过海量金融行业特有文档(如复杂对账单、年报、招股书等)进行二次训练和微调的,使其能更深刻地理解金融领域的上下文和版式。其次,其强大的溯源能力可以将每个抽取结果精准定位回原文,极大地方便了人工核验,形成了一个“AI处理+人工校验”的质量闭环。





