
EN
在企业数字化转型的深水区,智能文档审核已成为提升业务效率(如财务报销、信贷审批、供应链结算等)的核心环节。
然而,面对海量的业务单据、合同与凭证,许多团队在推进文档解析项目时发现,真正的痛点是在于“识别后如何流转与校验”。
传统的 OCR 技术大多局限于单点识别。由于前端资料进来时常常是多格式混杂的,系统无法进行有效的分类与前置处理;提取出的散乱字段也往往无法直接映射到业务审核规则中。这就导致后续的资料分拣、分类、校验和复核,只能继续依赖大量的人工补位。识别准确率再高,审核的综合成本却依然居高不下。要让文档解析系统真正在业务中落地并转化为生产力,关键不能只停留在单点识别,而是要将资料入口、字段抽取、规则配置和结果回看连成一条完整的审核流水线。
易道博识智能文档处理工作流(DocFlux),正是基于这一全链路框架构建的最佳实践。
如果前端资料仍然要靠人工分类,整体的审核效率依然很低。
易道博识DocFlux支持 PNG、JPG、JPEG、BMP、TIFF、PDF、XLS、XLSX、DOC、DOCX、PPT、PPTX、WPS 等海量格式,并支持 200M 大文件上传。更重要的是,它可以自动识别文档类型并进行智能分类,大幅减少人工预分拣的工作量。
以财务报销场景为例,当员工将混杂在一起的增值税发票、火车票、打车票甚至酒店水单一次性打包上传时,系统能够自动将它们精准识别并分流至对应的票种通道,大幅减少人工预分拣的工作量。
面对复杂的审核场景,易道博识DocFlux采用了“大小模型协同”的先进架构。大模型擅长处理非标长尾文档的泛化抽取,小模型则负责高频标准证件识别。
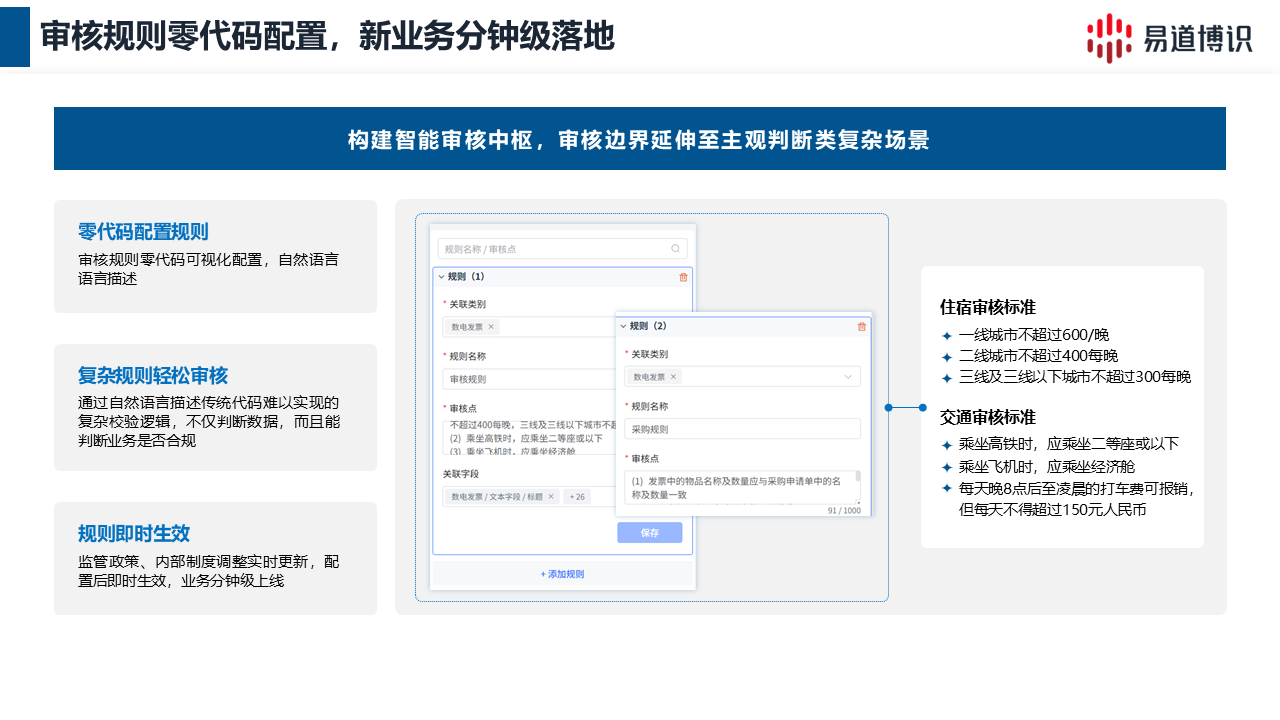
不少审核项目上线后,受限于审核规则的调整响应太慢,无法跟上业务的变化。 易道博识DocFlux支持可视化、零代码的规则配置,甚至支持用自然语言直接描述复杂的校验逻辑。对于规则频繁调整的审核场景来说,这意味着业务人员可以随时贴近业务动作调整规则,让规则变化不再成为上线的障碍。
落地之后,复核岗位最怕的是系统给出了审核结论,却说不清问题出在哪个字段、源自哪份原始单据。DocFlux支持直观的结果看板,并在原始单据中高亮标记出问题字段,让所有的审核结论都能精准溯源到源数据,满足审计要求。
因为识别率只回答“字有没有读出来”,没有回答资料能否自动分类、字段能否进入审核动作、规则变化能否快速响应,以及结果能否回溯到原始单据。落地失败通常断在这些环节,而不是断在单次识别。
资料来源复杂、格式混杂、规则经常调整、审核岗位需要频繁补录或返工的场景更适合优先推进,比如发票、合同、银行回单等复杂非标单据处理场景。
需要。系统更适合承担分类、抽取、规则执行和问题定位,人工复核仍然负责业务判断和边界确认。好的落地方式不是取消人工,而是把人工从重复搬运资料,转到更有价值的复核动作上。





