
EN
金融行业对文档处理效率与精度的需求正在越来越重要,从繁杂的合同文本到详尽的财务报表,从多样化的个人证件到专业的审计报告,这些海量文档数据构成了金融业务的核心支撑。然而,传统的光学字符识别(OCR)技术在复杂版式、低频场景或未知文档类型的处理中常常显得捉襟见肘,暴露出通用性不足、开发成本高昂以及资源利用率低下等问题。
为此,易道博识GIE(General Information Extraction)大模型应运而生,以其卓越的泛化能力和创新的技术架构,为金融文档处理带来了革命性的改变。本文将从OCR大模型的视角,系统探讨GIE大模型的技术原理、功能特性、应用场景及其核心优势。
传统OCR技术虽在特定文档识别中表现尚可,但其局限性在数字化转型加速的背景下日益凸显。针对固定版式的文档,传统小模型尚能胜任,可一旦面对新版式或非结构化内容,识别精度便大幅下降,且新增字段的适配需耗时数周甚至数月进行数据采集、标注和模型重新训练。此外,多模型分散部署的模式导致硬件资源利用效率低下,管理数十甚至数百个模型和API接口的成本居高不下。
针对上述行业痛点,GIE大模型,作为一款基于海量金融文档数据训练的OCR大模型,深度融合版式特征与语义特征,实现了无预设版式的高精度识别能力。这一模型摒弃了传统技术对关键字和固定版式的依赖,通过泛化能力,轻松实现对各类文档、凭证和票据的结构化处理。
更为关键的是,GIE大模型将复杂多模型管理简化为单一API接口,不仅显著提升了资源利用效率,还大幅降低了维护成本。
GIE大模型的优势在于其对版式学习和语义理解的双重能力。依托银行、证券、保险、财税等多个行业文档数据的深度训练,GIE具备了丰富的版式特征解析能力和强大的语义分析能力1。这种特征融合技术使模型无需依赖预设模板,即可精准识别复杂表格、多栏版式及含图形元素的多模态文档。
只需要配置提示词(Prompt),即想要抽取的信息字段便可进行抽取避免了针对每类文档进行繁琐标注与重新训练的麻烦。
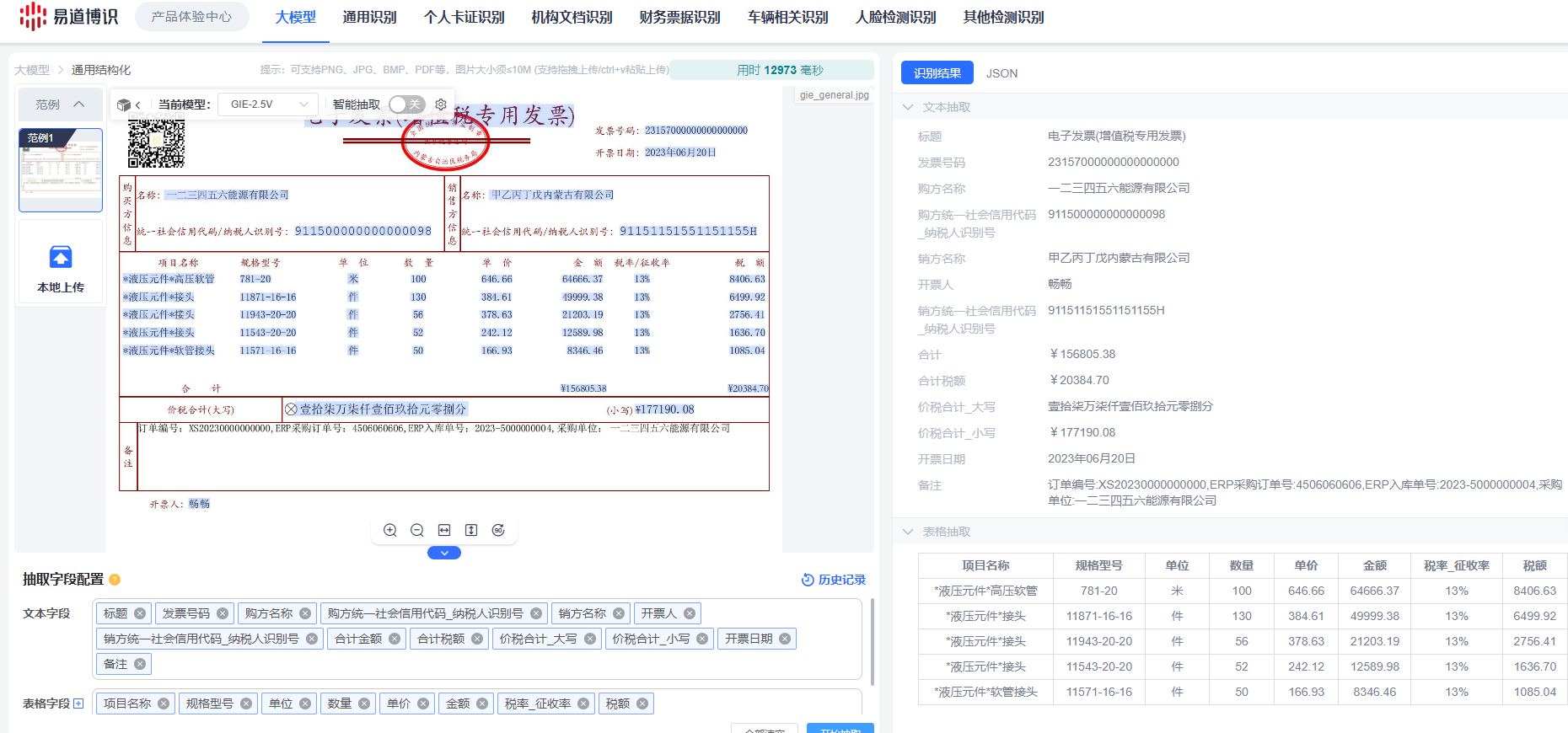
在产品设计上,GIE大模型充分体现了灵活性与高效性。它通过单一API接口覆盖所有文档识别场景,无论是结构化数据还是非结构化内容,均能无缝处理。同时,GIE提供多模态版本(如GIE-2.5V)和轻量化版本(如GIE-Lite),可根据实际需求灵活切换参数量,以节省计算资源1。在数据安全方面,GIE支持本地化部署,确保数据处理全程不出机构内部,同时适配主流国产信创环境及英伟达推理卡(如T4、A10),实现软硬一体化交付。
在信贷审批过程中,金融机构需处理大量身份证明、财务报表及合同文件,传统人工录入与审核效率低且易出错,而GIE大模型可自动结构化各类文档,精准抽取关键字段,降低人工核验成本和业务风险。
在合同管理中,面对多栏版式、跨页表格等复杂排版,GIE大模型凭借多模态处理能力准确提取关键条款,支持文本与表格独立配置,极大提升合同处理效率。
此外,GIE大模型在银行“两录一校”业务中也表现优异。传统模式下一笔业务数据需两名人员录入并由第三人校对,人工成本极高,而GIE大模型与小模型结合,通过同步录入及自动校验构建数据质量双保险,仅需少量异常情况人工审核,大幅减少人力投入。
相较于传统OCR解决方案,GIE大模型在多个维度展现出显著优势。传统方案响应新需求时需经历漫长开发周期,而GIE大模型通过简单配置提示词最快数小时内即可上线新功能,极大地缩短响应时间并降低IT开发与硬件维护成本。同时,GIE大模型摒弃特定文档类型限制,支持多版式、富格式文档处理,零样本泛化能力让企业面对低频或未知文档时无需重新开发模型。
展望未来,可以预见,随着GIE大模型的不断完善与推广,其影响力将在金融乃至更多领域持续扩大,成为推动数字化转型的重要力量,解决传统OCR技术在通用性、成本方面的瓶颈,,为企业创造实实在在的价值。
问题1:易道博识的GIE大模型如何提升银行“两录一校”效率?
回答:易道博识的GIE大模型与小模型同步录入单据信息,自动比对校验,代替人工双录和校对,仅少量异常需人工审核,大幅降低人力成本并确保数据质量。
问题2:易道博识产品如何处理金融文档的复杂版式?
回答:易道博识的GIE大模型支持多版式和非结构化文档抽取,无需标注训练,配置提示词即可精准处理复杂表格和多栏版式。
问题3:易道博识的GIE大模型如何保障金融数据安全?
回答:易道博识的GIE大模型支持本地化部署,数据处理全程不出机构内部,同时适配国产信创环境,确保金融数据安全无忧,兼顾成本与性能。





