
EN
金融机构在日常运营中处理海量文档。这些文档类型多样,格式复杂,是业务运营的基础。如何高效、准确地处理这些文档,直接影响机构的运营效率与风险控制水平。新一代的OCR大模型技术为此提供了有效的解决方案。它提升了文档处理的自动化程度与数据提取的准确性。
本文将阐述传统OCR技术的局限性,介绍OCR大模型的核心技术优势,并通过以“易道博识GIE”为例,展示该技术在金融核心业务中的具体应用。
传统OCR技术主要依赖预设模板或规则进行文字识别。OCR大模型则基于海量数据的预训练,使其能够直接理解文档的版式布局与逻辑结构。它不依赖模板,即可从任意格式的文档中提取结构化信息。
传统OCR技术在应对现代金融业务时,暴露了明显的技术局限。
●文档类型多样化:金融业务涉及标准证件、半结构化报表和非结构化合同。文档种类繁多,形态各异。
●版面布局复杂化:文档普遍存在多栏排版、跨页表格、印章遮挡和手写文字。这些因素增加了机器自动提取信息的难度。
●业务要求高度化:在信贷审批、保险理赔等核心业务中,处理延迟或信息错误可能引发业务风险。人工处理效率低、成本高,难以满足业务高峰期的需求。
传统OCR技术的短板主要体合现在以下三点:
1.泛化能力弱:技术对新版式或版式微调十分敏感。每当出现新格式,就需要重新投入人力进行数据标注与模型训练,适配周期长,成本高。
2.识别精度不足:面对图像质量不佳、布局复杂或印章干扰的情况,识别准确率会显著下降,导致信息提取不完整或错误。
3.缺乏深层理解:传统OCR停留在“识别文字”的层面。它无法解析字段间的逻辑关系,例如,无法关联财务报表中某个项目与其对应的多年期数据。这阻碍了信息的深度利用。
这些局限性制约了金融业务的自动化与智能化进程。
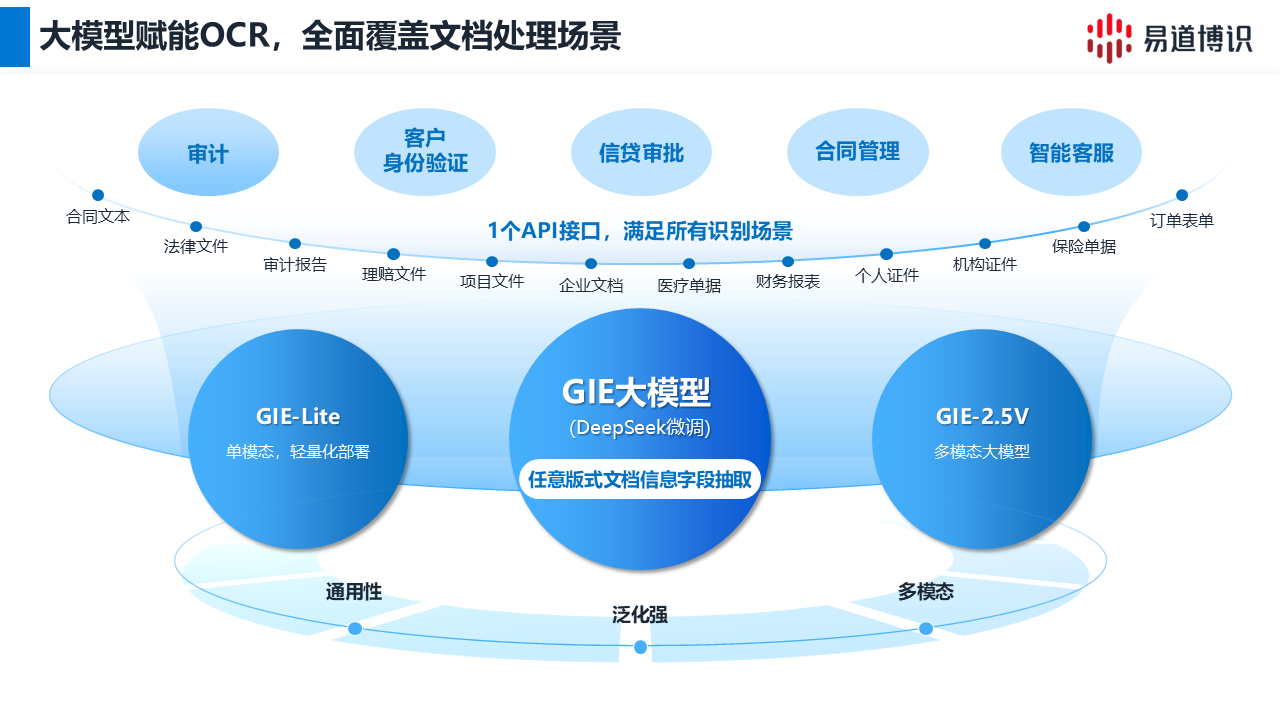
为解决上述问题,易道博识推出了GIE(通用信息抽取)大模型,实现了从“文本识别”到“内容理解”的转变。它能深度解析文档的版面布局、逻辑结构和元素关联,实现对任意版式文档的信息抽取。

其核心技术优势包括:
1.卓越的版式泛化与解析能力
OCR大模型无需依赖固定模板,展现出强大的版式识别能力。
●复杂表格解析:可准确识别跨页、无线框、嵌套等复杂表格的结构,恢复单元格的行列对应关系。
●多场景版面适配:能自动识别多栏、图文混排等复杂布局,准确定位并提取指定信息。
●强大的抗干扰性能:在印章遮挡、复杂水印或手写批注等干扰下,模型依然能保持较高的识别与提取准确率。
2.“Prompt即应用”的敏捷配置模式
用户通过输入简单的自然语言指令,即可快速定义新的信息提取任务,无需进行代码开发或模型重训。该模式极大降低了技术使用门槛,也显著缩短了新业务的适配上线周期。
3.全面的国产化生态支持
在金融信创领域,技术自主可控是基础要求。先进的OCR大模型在研发之初就将国产化适配作为核心策略。例如,易道博识GIE模型深度适配了鲲鹏、飞腾等国产CPU与统信UOS、麒麟等国产操作系统,确保了技术在金融信创环境下的性能与稳定性。
OCR大模型将海量的非结构化数据处理成高质量的结构化信息,为上层业务应用和决策分析提供了支持。
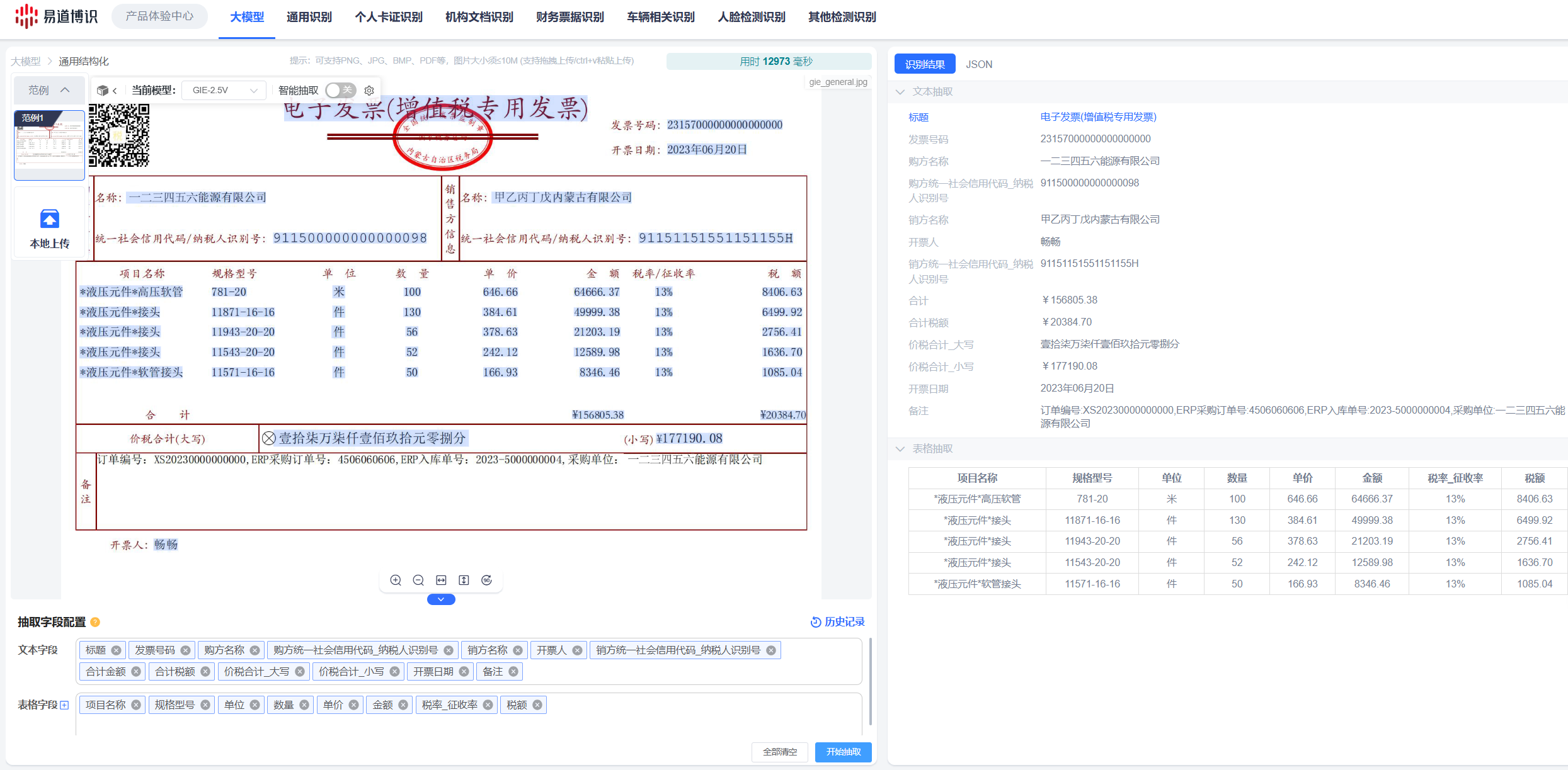
●信贷审批业务:
○传统方式:人工审核企业财报、银行流水、购销合同等全套资料,流程耗时数日。
○应用后:系统抽取关键财务指标,辅助生成结构化评估报告。审核周期可从数天缩短至小时级。
●保险理赔业务:
○传统方式:人工录入理赔申请书、医疗发票、诊断证明等单据信息,处理流程长。
○应用后:系统自动从各类单据中提取出险人信息、诊疗项目、费用明细等关键字段,完成自动化的初步定损和案件分级,加速理赔流程。
●财报分析业务:
○传统方式:分析师手动从PDF格式的年报、季报中摘录数据,工作重复且耗时。
○应用后:系统深度解析上市公司的财务报告,精准提取资产负债表、利润表、现金流量表中的所有数据,形成可直接用于分析的结构化数据库。
以通用信息抽取为核心的OCR大模型,通过其强大的版式理解能力、以及对信创环境的良好支持,为金融文档自动化提供了更优的技术路径,有效提升了金融机构处理非结构化数据的能力。
了解易道博GIE大模型如何应用于您的具体业务场景,优化文档处理流程,并提升数据利用价值。






